2.1 Descriptive statistics
As a reminder, descriptive statistics are used to summarize, organize, and overall describe our sample data.
2.1.1 Data variables
First, it’s important to understand the different types of variables in jamovi and how they map onto our levels of measurement.
Variables in jamovi can be one of three data types:
- Integer, meaning the values are discrete whole numbers
- Decimal, meaning the values are numbers with decimals
- Text, meaning the values are alphanumeric, not just numeric
Furthermore, variables in jamovi can be one of four measure types:
 Nominal
Nominal Ordinal
Ordinal Continuous (meaning jamovi combines interval and ratio and doesn’t distinguish between the two)
Continuous (meaning jamovi combines interval and ratio and doesn’t distinguish between the two) ID (used for any identifying variable you likely wouldn’t ever analyze, like participant ID number or name)
ID (used for any identifying variable you likely wouldn’t ever analyze, like participant ID number or name)
There are a few great things about jamovi when it comes to these data variables. First, jamovi will try to automatically determine what the data and measure types are when you type in data or when you open a dataset; this is fabulous, until it goes wrong. It’s important that you always double check your data and measure types first!
Second, those little icons will be really helpful to let you know what variables can go in which boxes. For example, we would never analyze a nominal variable as our dependent variable for a t-test, and jamovi will help remind you of that. When performing an independent samples t-test, the dependent variables box will have a little ruler icon indicating you should be putting continuous variables in that box. Similarly, it will tell you to put nominal or ordinal variables in the grouping variable (independent variable) box. Sweet!
2.1.2 Describing your data
We explore our data partly to describe our data and partly to check our data before performing inferential statistics. jamovi puts all our descriptive statistics into one useful analysis under the Exploration tab called Descriptives. Whenever you want to understand the measure of central tendency or dispersion of a single variable (e.g., what is the average score on a particular scale?) then you’ll go to the Descriptives analysis under Exploration.
In the Descriptives analysis, these are under the Statistics drop-down menu. There are a ton of possible options!
- Sample size: you can ask for the sample size (
N) and number of missing values (Missing) - Percentile values: these are useful for creating quartiles (
Cut points for 4 equal groups) orPercentilesof various sizes. - Dispersion: you should already be familiar with most of the measures of dispersion, particularly the
MinimumandMaximumand theStd. deviation(SD) andVariance(which is just SD2). We’ll learn about theS. E. Meanlater. - Central Tendency: similarly, you should also be familiar with all of the measures of central tendency:
Mean,Median,Mode, andSum. - Distribution: you should also be familiar with both
SkewnessandKurtosisand later we will learn what those values mean and how that helps us test for normality - Normality: lastly, there is a statistical test for normality called the
Shapiro-Wilktest that we will learn about later.
2.1.3 Writing up descriptive statistics
We’ll learn more about writing up our inferential statistics results later, but first let’s learn how we might report our descriptive statistics.
In small examples, we might write-up our descriptive statistics into a paragraph1:

In examples with many variables, we might write-up our descriptive statistics into a table2:

2.1.4 Visualizing your data
“A picture is worth a thousand words,” and in a world in which journal articles have word count limits, figures and graphs are priceless. They are also an incredibly powerful way to examine your data because it can often illuminate patterns you may not be able to see through a table.
jamovi has some plots built into its platform, both under the Plots drop-down menu in the Descriptives analysis and as options for many of the inferential statistical analyses.
We’ll learn more about how to choose and conduct better data visualizations later, but for now here are some recommended visualizations depending on what you are trying to do.
When you want to visualize the distribution of a continuous variable
First, there are two Histogram options: Histogram and Density. These are useful for seeing the overall distribution of your data and to help check for normality. Which should you use? I think they’re both pretty great, and in fact you can combine the two to have a histogram plot with a density overlay. I like this option best.
When you want to visualize the distribution of a continuous variable split by a categorical variable
There are three options under Box Plots: Box plot, Violin (which is really a density plot with its mirror image!), Data (which can be Jittered or Stacked; I prefer Jittered so you can see the density of data points really well), and Mean. Personally, I love checking all four boxes! This gives you the best of all them: the distribution of your data with the Violin option, the quartiles and mean with the Box plot option, a visualization of all your data points using the Data option, which is really useful because the other two options can be hiding weird things in your data, and what the Mean is.
When you want to visualize the frequencies of a categorical variable
For this you would choose the single option under Bar Plots: Bar plot. It will simply show the frequencies of a categorical variable.
```{block, type=“info”}
Remember: it is incredibly important to always visualize your data! You never know what descriptive statistics may be hiding.
```
2.1.4.1 Expanding your data visualization
Although these can be useful plots, I often do most of my data visualizations in other platforms. For most of my work, I use Excel because I find it pretty easy to make beautiful graphs. Here’s an example of a visualization I made in Excel3:

For some more complicated figures, I turn to the ggplot2 package in R. Here’s an example of a visualization I made in R4:
In this class, we’ll learn about effective data visualization later in the semester. I will provide some brief tutorials to help you get started, but please note that learning data visualization should be a course unto itself, so we will not be able to cover everything.
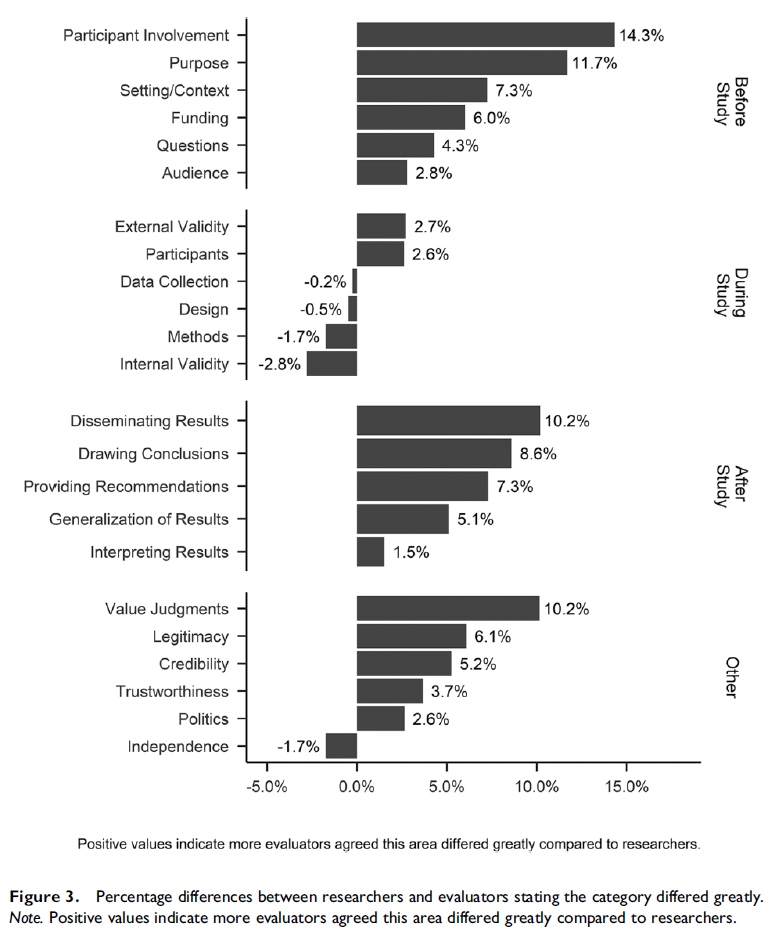
This comes from Wanzer (2017) Developmentally appropriate evaluations: How evaluation practices differ across age of participants↩︎
This comes from Wanzer et al. (2020) Experiencing flow while viewing art: Development of the aesthetic experience questionnaire↩︎
This comes from Wanzer et al. (2020) Promoting intentions to persist in computing: An examination of six years of the EarSketch program↩︎
This comes from Wanzer (2020) What is evaluation? Perspectives of how evaluation differs (or not) from research↩︎